
Readable code - a prerequisite for success
Developers spend most of their time reading and maintaining existing code. They try to understand what it actually does and how to improve it or expand it with new possibilities. Despite this, one often thinks only about the performance of the code, but not about its readability and maintainability.
When we're building software that should have a long lifespan, readability should be just as important as performance - readable code helps greatly in maintaining, adding new functionality, changing old, etc.
An additional benefit occurs when onboarding new developers - successful onboarding largely depends on the readability of the existing code.
When you're working on a product that's been in development for many years, you're bound to have to deal with legacy code that most likely wasn't written by you. When that code has thousands of lines and is not readable at the same time, any intervention becomes a huge source of frustration.
At Mediatoolkit, we approach development with the idea of long-term sustainability; with the rest, specifically, we put extra effort into creating readable code.
To be completely honest, until a few years ago we didn't pay too much attention to it, and it happened that we had big problems when upgrading features, and also when onboarding new people. But we learned from our mistakes.
The motive of this blog is that others do not repeat our mistakes and start writing clean code in time. Here are some good practices that we follow at Mediatoolkit to ensure code readability.
Readability is important
As we said, developers spend most of their time on existing code. If some part of the system has been developed over a period of several years, it is almost certain that a significant amount of time will be spent deciphering what the code does and how to modify it to meet new requirements. The question arises - what to focus on when writing code to make it readable and long-term sustainable?
Therefore, the first steps are as follows:
- Using meaningful terminology
2. Improvement of functions
3. Giving preference to immutable code (immutability)
4. Declarative over imperative programming
5. KISS principle
6. DRY principle
7. YAGNI principle
Using meaningful terminology
We name every part of the code and that's why it is necessary to do it well. Meaningful names give context, and explain what's going on. Variable and method names should explain the intent behind the produced code - why something is there, what it does, and how it's used. Take the time to come up with a good nomenclature - otherwise, you could spend a lot of time just trying to figure out what you wanted to express through meaningless names.
Here's an example of code with nonsensical names:
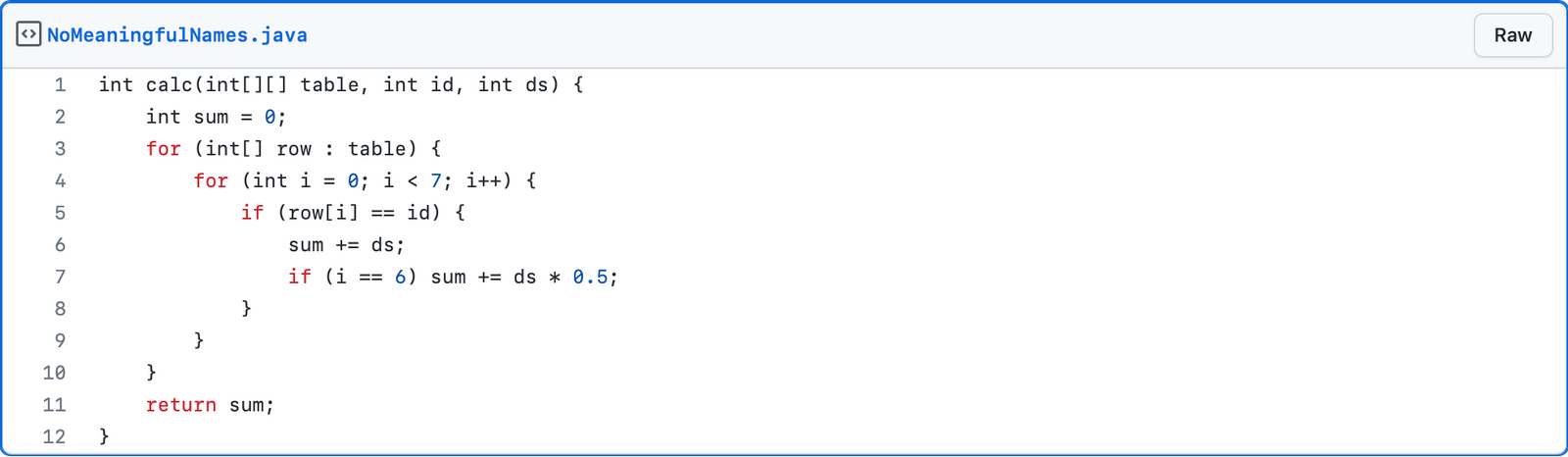
The same code, but with a meaningful nomenclature:
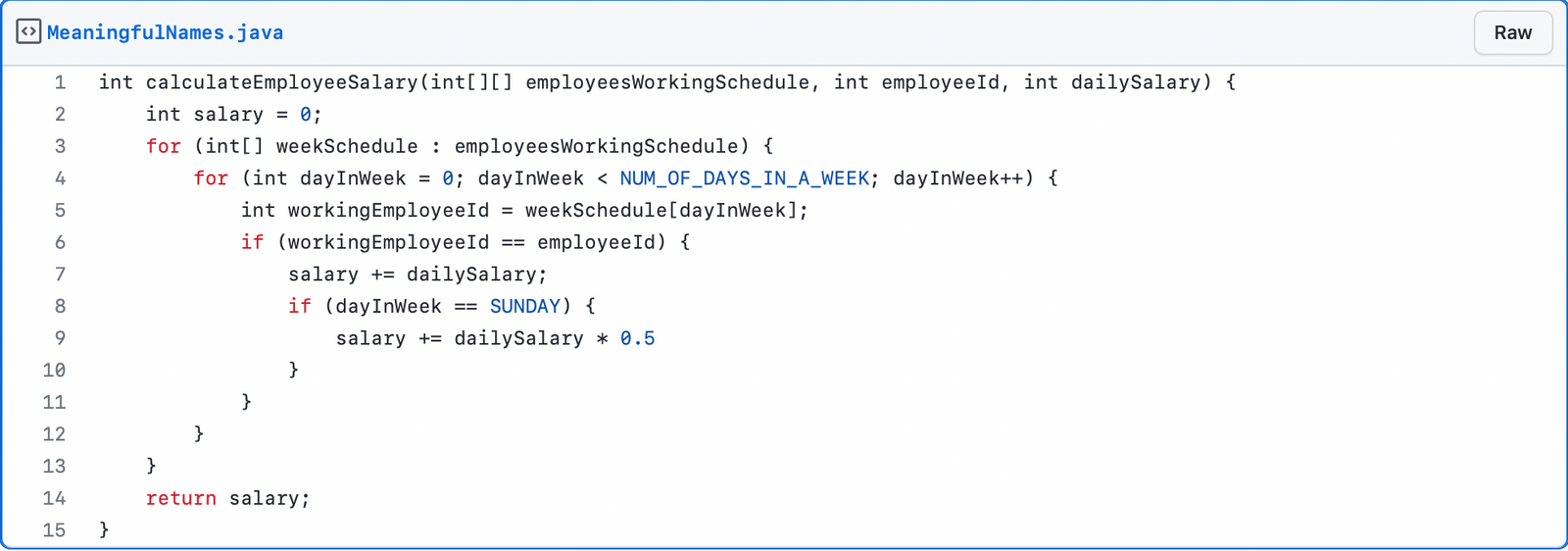
Naming should come from the problem domain whenever possible. It is not desirable to use technical names if there is a better name in the domain.
Classes and objects should have a noun in their names (customer, emailSender, htmlParser). A common mistake is to use too general nouns that by themselves do not give much meaning, especially not within the domain of the problem (data, info, manager, processor, controller...).
For example, an object called info is much harder to read than userInfo. Also, it is possible to have more info in a block of code, so it is easier to follow the logic when the names are as specific as possible.
Methods should be named using verbs (postPayment, deletePage, insert). It is a good practice to avoid abbreviations because they are usually understandable only during the initial development, while they can become confusing over time.
An example of a bad variable name, with a comment explaining the variable, is a common bad practice:

A better alternative is always:

A good practice is to choose one term per concept and stick to it. For example, instead of using fetch, retrieve, or get for the same retrieval mechanics in a project, you should choose one expression to stick to. Otherwise, the person reading the code often wonders why similar things are named differently and how the behavior of such things differs, when they are already consciously named differently.
Improvement of functions
The first thing that can be done is to reduce the functions, ideally to less than 15 lines of code. With smaller functions, we reduce the context that we have to keep in our head while reading the logical unit in the code.
Code indentation also helps keep context. It should preferably be kept to 1-2 levels of indentation in function, while more than that should be well justified. If possible, overly indented code should be replaced with a new function call.
An example of a good function simplification can be seen at:

To improve readability, functions should be responsible for strictly one thing. Large functions are often responsible for many things and should be divided into several smaller functions. Functions that call other functions should still be responsible for only one thing, just at a higher level of abstraction.
Introducing multiple layers of abstraction
It is easier to understand a large number of functions of a higher level of abstraction than a small number of low-level functions. Therefore, it is good to introduce a higher layer of abstraction whenever possible.
Abstractions should be based on domain behavior; arbitrary choice of abstraction can often spoil code readability.
The next rule for functions is that they should have as few arguments as possible; more than two arguments should be the exception, not the rule. Many arguments make it difficult to understand the code, especially in cases where the arguments are changed through the function and the changed ones are used as function results.
In general, a function should be either a statement that performs some action or a query that returns the desired data to the caller, never both. The naming should make it clear what the function's role is.
Functions should only exceptionally have side effects, and if they do, they must be explicit. It is very important for easier readability that the functions are clean, i.e. they do not change their state after the call (stateless).
Using immutability
Immutability is a property that guarantees us that the object/variable will not change after it is created. Immutable code creates copies of objects that have changed state.
Example code that changes state:

The same problem is solved with code that doesn't change the state of objects:

This property makes the code easier to follow. Knowing that objects are immutable, we don't need to worry if a function changes them. Also, it is easier to implement multi-threaded systems - immutable objects are thread-safe and we don't need to surround them with synchronization blocks.
Sometimes it will not be possible to achieve simple logic and readable code with the condition that the code is immutable - in such cases, it is fine to resort to mutable code, but its reach should be minimized.
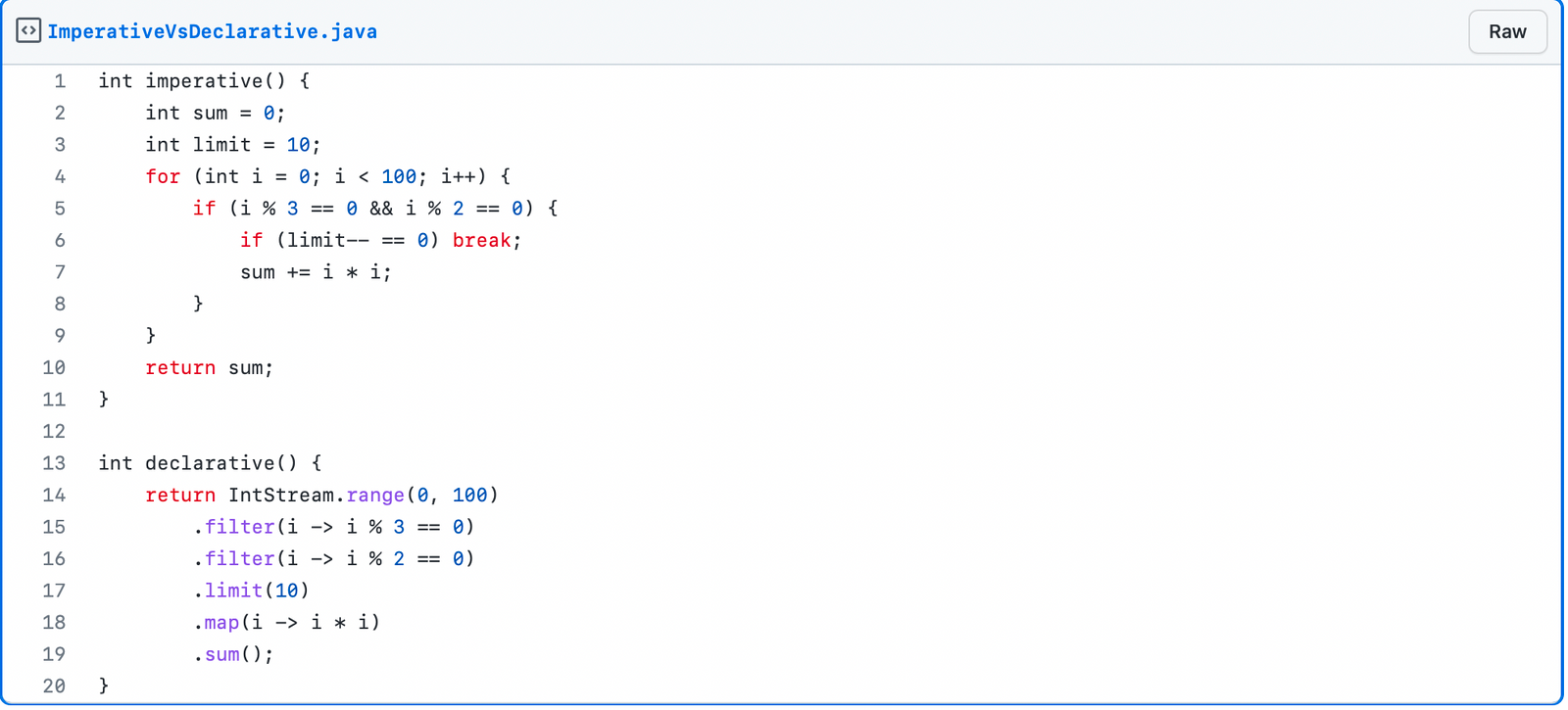
Declarative over imperative programming
Imperative programming says how things should be done; step by step, conditionals, loops, etc. On the other hand, declarative programming tells what to do, not how; it is built on top of the imperative mode.
The declarative style is much clearer when expressing the business logic and intent of some code. When a new person starts reading some code, it makes it a lot easier for them when they first see what the intention of that code is and thus enables them to dive into the relevant part of the code faster. With imperative mode, it is often the case that you first need to read the entire code in order to understand what that code does.
An example of the same method written imperatively compared to the declarative way:
KISS principle
Programmers often know how to come up with "genius" solutions to some problems, no matter how much such solutions increase the complexity of the code. The reasons can be various - from trying out new techniques, and feeding the ego, all the way to the nature of the programmer himself. However, simplicity should come first - if at all possible, unnecessary complexities should be avoided. The English name itself describes the idea very well: "Keep it simple stupid" (KISS)
DRY principle (don't repeat yourself)
Code duplication is something that should generally be avoided; we should strive to have one place where some kind of knowledge takes place. If we have a duplicate block of code per project, the problem arises when changing those blocks - we have to remember where we duplicated the same code and make changes in all those places. Copying blocks of code is fine in moments of rapid prototyping, but as soon as that code moves towards something more serious, it needs to be cleaned of all potential duplicates.
YAGNI principle (You ain't gonna need it)
We should not implement things that we "might" need in the future, but only what we definitely need. Premature implementation closes off the possibilities of designing the system in the best way - often the product ends up being designed for the things we might need, rather than what we really need it for.
Conclusion
By following the above principles (and a few more), at Mediatoolkit we've managed to keep most of our code and design readable, easily maintainable, and upgradeable. We also made the onboarding experience easier for new colleagues by making touching existing code a pleasant experience.

