
Into a World of Data: A Guide to the Data Engineer Role
"Data is the new oil", is a well-known phrase that turned out to be completely true. In the world today, practically every action is translated into data, and companies have widely recognized the importance of data for the organization. This is where the role of Data Engineer appeared, as a key person for collecting and managing large amounts of data.
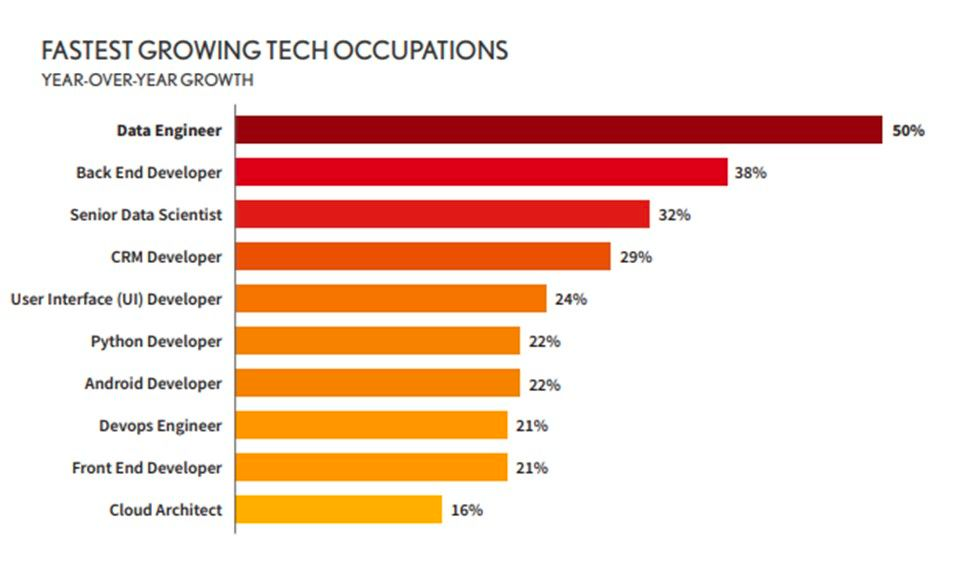
According to Dice's 2020 tech report, the demand for Data Engineers saw a 50% increase, and the pandemic has further accelerated that trend.
If you are also thinking about this role, you are interested in the world of data, or maybe you are already working on it without even realizing it, you are in the right place because further on in the text we will clarify what it actually entails and remove the misconceptions that accompany it.
A review of this role and the personal experience of Dejan Mijatović, recently part of the newly formed Data Team at the level of the Global Delivery Center at the Zühlke company, will help in this. Having previously worked as a Software Engineer, Dejan arrived at Zühlke first as a .Net Full-stack Engineer, and for someone with many years of Python experience and a passion for everything that has data in it, the path to Data Engineer was natural.
What does a Data Engineer actually do?
The Data Engineer is the person responsible for creating and maintaining the data pipeline, for collecting, transforming and storing data, and works closely with Data scientists and analysts to understand what the data will be used for and in what form it should be stored.
Data Engineer != Data Scientist
Before we bring this role closer to you, it is important to clarify that a Data Engineer is not the same as a Data Scientist. Although the differences are much greater than is usually thought, confusion is most often introduced by the common data in the name, while the second part hints at the distinction.
As Dejan explains to us, while one is an engineer and deals with data logistics problems, the other is a scientist who uses research methods to extract value from them.
The problems they solve differ, as does the approach to solving those problems, the background, and the skill set required. Very often this is also a different type of person, with a different way of thinking and probably a different academic education, so while a Data Scientist mostly has a background in mathematics and statistics, a Data Engineer comes mostly from electrical engineering faculties, computer sciences, applied mathematics or some other IT field.
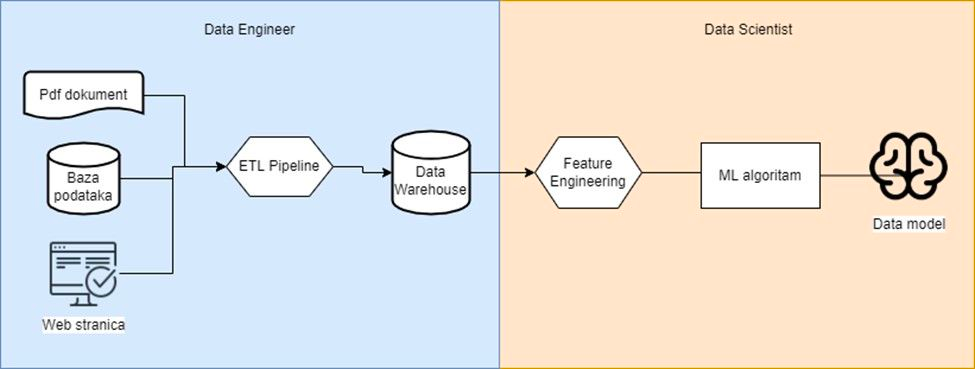
The picture above shows a simplified example of a data pipeline in which the collected data is used to train ML (machine learning) models and divide the responsibilities in that scenario. We see that where the Data Engineer's job ends, the Data Scientist's begins.
Dejan also emphasizes that data consumers do not have to be only data scientists. It is important to note that the vertical line dividing the two rolls can be shifted to one side or the other depending on several factors such as the complexity of the data pipeline, the skill set of the engineer and above all the size of the project, i.e. given to the team.
While on larger projects, the duties of a Data Engineer will be close to the job description, the reality is that on smaller projects it will be expected to cover the entire flow of data, from collection and storage, to analysis and creation of models, practically covering the duties of a Data Scientist. Therefore, it can be said that it is a full stack Data Engineer - points out Dejan.

What skills does a Data Engineer have?
If you were to read a job ad, the description for this position would look something like this:
Required skills:
● Knowledge of relational and NoSQL databases
● Python, preferably Java
● Knowledge of ETL and ELT pipelines
● Knowledge of algorithms and data structures
● Automation and scripting
● Knowledge of big data tools such as Kafka or Hadoop
● Understanding of distributed systems
● Containerization
● Experience working with AWS, Azure or GCP
Responsibilities:
● Creation, maintenance and testing of data pipeline architecture
● Collected data from various sources
● Developing algorithms for transforming raw data into a useful, usable state
● Close collaboration with stakeholders to understand the company's need for data
● Designing APIs for data access
● Concern for safety and security of data
As you can see, and Dejan confirms, the Data Engineer role requires strong technical knowledge. Who then has the best prerequisites for it?
I would say that the fastest way to become a Data Engineer is for software engineers who know the Python programming language, preferably Java, and a good knowledge of database systems, writing SQL queries, database modeling and knowledge of cloud technologies. If the engineer has all this knowledge and skills, learning data engineer-specific tools like Spark or Airflow is an easier part of the job. The biggest challenge is understanding the data and the whole set of new problems that come with it, and the only correct way to learn is through experience - explains Dejan from his own experience.

Python does not mean data, but data means Python
Another misconception in the data world is equating knowing Python with knowing data, be it engineering or data science.
The fact, Dejan points out, is that Python is currently the most used programming language in this area, but that is certainly not its only purpose.
As the language used on the Mars Rover, the new James Webb space telescope that powers millions of websites including Reddit, Dropbox and Instagram, it would be unfair to confine Python to just a given field, and it would be unfair to expect someone to learn the language immediately and thus qualifies for working with data - says our interlocutor.
Data Engineer and ML
Although we have already explained that ML is part of the Data Scientist's responsibilities and have not counted as a necessary knowledge for the role of Data Engineer, a basic knowledge of the field is very useful.
Stating why, Dejan points out that it enables a better understanding of their needs and other end users of that data, and Pytorch, Tensorflow and Scikit learn are today the leading open source libraries for ML and DL.
New position, old problems
Although data engineering is a relatively new position and is still in development, the problems it solves have certainly been known to you for a long time. They were only mainly handled by DB administrators or Software Engineers, and as the volume and complexity of the problem increased, a need was created for a new role, which would deal exclusively with it.
"Knowledge of tools like Airflow, Hadoop or Spark does not necessarily make someone a Data Engineer. Of course, all these tools have made work easier and faster and opened up new opportunities, but what makes someone an expert in the field is understanding data as a field and all the problems that come with it. When creating a data pipeline, the Data Engineer will very quickly encounter problems such as data unavailability, different or non-existent data structures, geographical distribution, consistency, reliability and, above all, quantity. Because if we talk about data and Data Engineer, the term big data is mostly there" - points out Dejan and interestingly notes the following:
There are even many data engineers who are not even aware that they are, because it may not be written next to their name or they do not have such a division in the company. The reason may be that the implemented way of solving this is different from modern solutions, or the fact that they are not currently using popular tools to build a data pipeline. Certainly, the problems they deal with make them data engineers, namely working with large amounts of data, taking care of scalability, data transformation and working in distributed systems.
What next?
Most of today's senior Data Engineers are mostly Software Engineers who came from other fields, acquiring new knowledge along the way.
As someone who went through a similar transition himself, Dejan testifies that the biggest challenge is getting to know the new problems that the field brings, and only then learning new tools such as Airflow or Nifi. Of course, previous Python experience and working with distributed systems definitely help.
If you're a software engineer, maybe your path is a little easier just because the learning list is shorter. If you already know some other object-oriented language, I'd say that's an advantage and learning Python will be easier for you. However, be careful in their differences, learn what Pythonista means and don't write Python like you would Java. And if you only know Python, be aware of its limitations - Dejan tells you.
Surely Dejan's explanations and experience helped you to understand to what extent the world close to you is given and whether you want to gain your first business experience in this field. His advice is to re-read the part of the text about the differences between Data Engineer and Data Scientist and think about where you see yourself, because each of these two fields is a career for itself.
If it's still a Data Engineer, perhaps the right solution for you lies among these positions because Zühlke is expanding its Data team! Get to know this company better through their profile on Joberty, where you will find all the currently open positions they offer.

